
Am 27.10.2025 hat Proxmox einen Fehler im Proxmox Backup Server mit der Bezeichnung PSA-2025-00019-1 bekannt gegeben. Eine Race Condition mit der Möglichkeit von Datenverlust hört sich im ersten Moment extrem gefährlich an. Es kommt aber selten vor und Proxmox hat es mit der Version 3.4 behoben. Die neue 4er Version des PBS hatte diesen Fehler nie.
Quellen von Proxmox und Sercurity-Sites:
https://forum.proxmox.com/threads/proxmox-backup-server-security-advisories.149332/post-811601
https://wid.cert-bund.de/portal/wid/securityadvisory?name=WID-SEC-2025-2416
https://www.heise.de/news/Proxmon-Backup-Server-Angreifer-koennen-Backup-Snapshots-zerstoeren-10961168.html
Aber was passiert dort nun, bzw. wie passiert dieser Fehler?
Da müssen wir mit ein wenig Theorie starten. Die Daten der Sicherungen werden in Chunks auf dem Filesystem des PBS gespeichert. Die Chunks sind aber keine kompletten Sicherungen, sondern nur kleine Teile der Sicherungen. Die eigentlichen Sicherungen sind dann „Snapshots“. Diese Snapshots verweisen auf die Chunks, sie beinhalten aber keine Nutzdaten, nur einige Meta-Daten. Wichtig hierbei, ein Snapshot verweist auf viele Chunks, aber auch die Chunks ansich, können in verschiedenen Snapshots enthalten sein.
Aber warum nun so kompliziert?
In dem Moment, wo man die Sicherung von den Daten trennt ist eine effektive Deduplizierung der Daten möglich. Der erste neue Snapshot (= die erste Sicherung einer VM) verweist komplett auf die unterschiedlichen Chunks auf dem PBS. Da bringt es noch keinen Vorteil. Kommt aber die nächste Sicherung der gleichen VM und es ändern sich nur wenige Daten, dann verweist der zweite Snapshot (= die zweite Sicherung) auf fast die gleichen Chunks, bis auf die Änderung, das sind dann wieder neue Chunks.
Was macht die Garbage Collection?
Wenn die Sicherungen verworfen werden, weil sie zu alt sind oder nicht mehr gebraucht werden, dann wird nur der Snapshot gelöscht, nicht aber die Chunks. Also die Metadaten sind weg, aber die eigentlich Nutzdaten sind noch zu 100% vorhanden. Wenn die jetzt nie gelöscht werden, dann wird der PBS irgendwann voll laufen. Und dafür gibt es die Garbage Collection.
Dieser Prozess wird zeitgesteuert gestartet und schaut sich alle Sicherungen an, also die SnapShots. Und aus den Snapshots die noch vorhanden sind, wird eine Liste mit allen Chunks gebaut, die noch benötigt werden. Das ist der erste Schritt im Garbage Collection. Der zweite Schritt muss dann nur noch alle Chunks löschen, die nicht auf der Liste stehen. Das ist einfach …
Aber wo ist das Problem?
Wenn jetzt die Garbage Collection startet, dann merkt sie sich die Start-Zeit und würde am Ende nur Chunks löschen, die älter sind. Damit werden keine neuen Sicherungen gelöscht, die nach dem Start in der Phase 1 der Collection neu angelegt wurden. Das ist nicht das Problem, es ist komplexer:
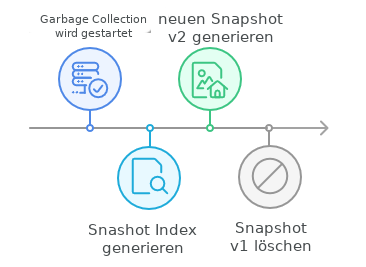
Starten wir die Garbage Collection (also den Job dazu) und wir betrachten eine VM mit einer Sicherung mit dem Snapshot v1 genauer. Allerdings liegen vor dieser VM noch deutlich mehr Daten (also andere Sicherungen von VMs), der Collection Prozess braucht eine gewisse lange Zeit. Jetzt machen wir eine neue Sicherung wieder von dieser VM und das wird der Snapshot v2. Soweit alles in Ordnung, das Löschen wird die neueren Chunks (die unsere neue Sicherung gerade angelegt hat) nicht anfassen. Wenn wir jetzt aber den Snapshot v1 löschen und der Collection Prozess ist dort noch nicht angekommen, dann verwerfen wir ja alte Chunks vom Snapshot v1. Der Collection Prozess wird also, wenn er bei unserer VM angekommen ist, den Snaptshot v1 nicht mehr finden. Den Snapshot v2 wird er aber ignorieren, da er ja später gestartet wurde.
Was passiert jetzt?
Alle Chunks die zu Snapshot v1 gehören kommen nicht auf die Liste (der Snapshot v1 ist ja nicht mehr da), alle Chunks von Snapshot v2 auch nicht, weil ja später erstellt. Obwohl die Chunks noch alle von v2 benötigt werden. Und so gehen wir jetzt in den Lösch-Prozess (das ist Phase 2) hinein. Unser Snapshot v2 verliert alle Chunks, die es schon in v1 gab. Sie sind nicht in der Liste und sie sind älter als das Start-Datum. In unserem Beispiel haben wir also nahezu alle Daten (= die Sicherungs-Chunks) unserer VM verloren. Ein Restore ist also nicht mehr möglich. Noch mal genauer: Die Chunks von v1 werden ja nicht mehr benötigt, aber auch v2 zeigt ja auf die gleichen Chunks und v2 wird noch benötigt. Also verliert v2 die Chunks, die gleich zu v1 waren. Nur die neuen Chunks bleiben bestehen.
Wie merkt man dieses Problem?
Na ja, nur in dem Moment, wo man einen Restore versucht und dieser fehlschlägt. Es gibt aber keine Fehlermeldung im normalen Betrieb, die Daten sind dann auch wirklich weg.
Was ist also zu tun?
Wenn man noch unterhalb der 3.4 bei PBS ist, dann auf jeden Fall updaten. Das ist das wichtigste. Und dann sollte man sich dieses Problem einmal zeitlich betrachten: Haben ich lange laufende Garbage Collection Prozesse und wird während der Laufzeit eine Sicherung durchgeführt und auch noch die Anzahl der Sicherungen reduziert. Wenn das im zeitlichen Verlauf gleichzeitig vorkommen kann und man noch bei der 3.3 war bzw. ist, dann könnte dies passiert sein. Augenmerk sollte man auf Sicherungen legen, die nur eine Version vorhalten, die sehr schnell in der Anzahl reduziert werden und natürlich auf die Laufzeit der Gargade Collection.
Ist man denn mit der 3.4 automatisch fehlerfrei? Nein, wenn dieser Fehler im Backup enthalten ist, weil er mit einer älteren Version entstanden ist, dann bleibt dieser Fehler bestehen. Er läuft nur irgendwann aus der Datensicherung heraus, wenn der Stand nicht mehr benötigt wird.
Schauen wir uns mal eine Konfiguration an:
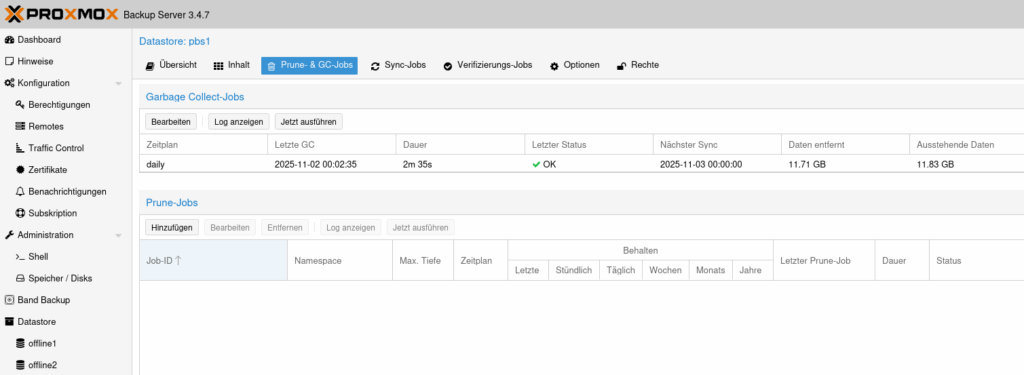
In diesem Beispiel läuft die Garbage Collection täglich um 0:00 Uhr, braucht aber unter 3 Minuten. Sollte jetzt aber eine Sicherung auch um 0:00 Uhr gestartet werden, die nur Sekunden braucht und direkt daran wird eine Version gelöscht, dann besteht Gefahr. Wobei im Log die Phase 1 noch deutlich schneller durch ist.
In diesem Fall wurden aber während der Garbage Collection nie Backups durchgeführt, um die Last für den PBS zu verringern. Also nur ein Zufall, der diesen Fehler verhindert hat.
